多模态模型如何重塑视觉创作
来源: 机器之心

架构突破:统一的多模态模型
OpenAI在2024年5月发布的GPT-4o标志着生成式AI的重大进化。与之前需要独立图像模型(DALL-E 3)的架构不同,GPT-4o通过端到端统一训练实现了:
- 文本/代码/图像的联合理解
- 跨模态知识共享
- 上下文感知的生成能力
传统diffusion transformer通过去噪生成图像的方式被革新为直接语义到像素的映射,这使得4o的图像生成具有以下特性:
- 精准指令跟随:可同时处理10-20个对象的复杂场景
- 动态上下文利用:能引用对话历史中的视觉元素
- 多轮迭代优化:保持角色/风格的一致性
核心能力解析
1. 文本-图像精准融合
模型展现惊人的文本渲染能力,能:
- 准确生成提示中的定制化标语
- 保持文字与视觉元素的自然融合
- 处理"Broom Parking"等创意文本
2. 商业级视觉设计
 高端餐饮菜单设计案例
高端餐饮菜单设计案例
在商业应用场景中,4o可以:
- 完美呈现所有指定文字内容
- 保持彼得兔插画风格的统一性
- 平衡传统韵味与高端质感
3. 动态迭代创作
多轮修改案例流程
通过对话式交互实现:
- 原始图像输入(猫咪照片)
- 添加侦探服饰配件
- 转化为游戏界面设计
- 最终加入RPG UI元素
4. 复杂指令解析
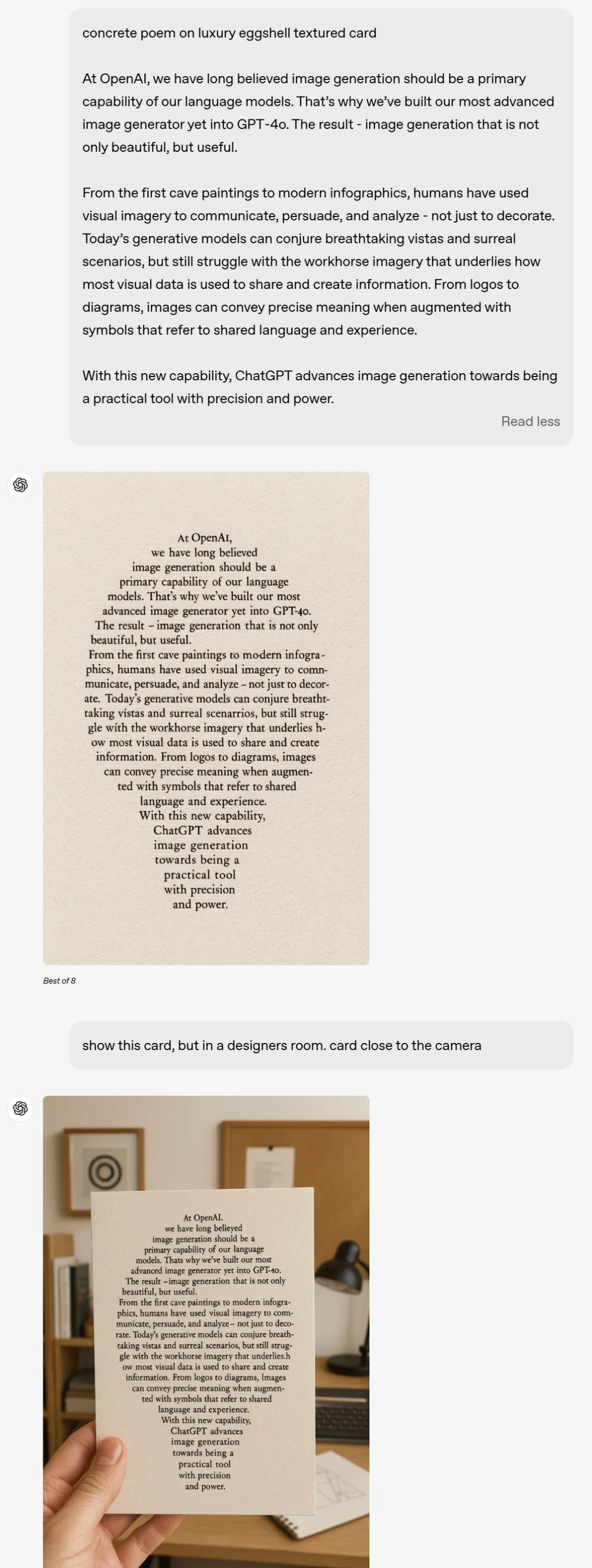 多对象空间排列测试
多对象空间排列测试
突破性表现包括:
- 准确排列4x4网格所有对象
- 正确处理彩虹闪电等抽象元素
- 保持每个对象的特征独立性
技术实现路径
OpenAI通过三阶段训练达成这一能力:
- 预训练阶段:50亿图像-文本对学习跨模态关联
- 对齐优化:强化指令跟随与细节控制
- 安全防护:内置内容过滤机制
应用前景展望
这项技术将深刻影响:
- 广告设计:实时生成营销素材
- 游戏开发:快速原型角色场景
- 教育培训:可视化复杂概念
- 零售电商:个性化商品展示
"这不仅是图像生成的进步,更是人机交互方式的革命。" — OpenAI首席技术官
